
Text-to-video generators: a comprehensive survey
by Martinraj Nadar | Friday, Nov 14, 2025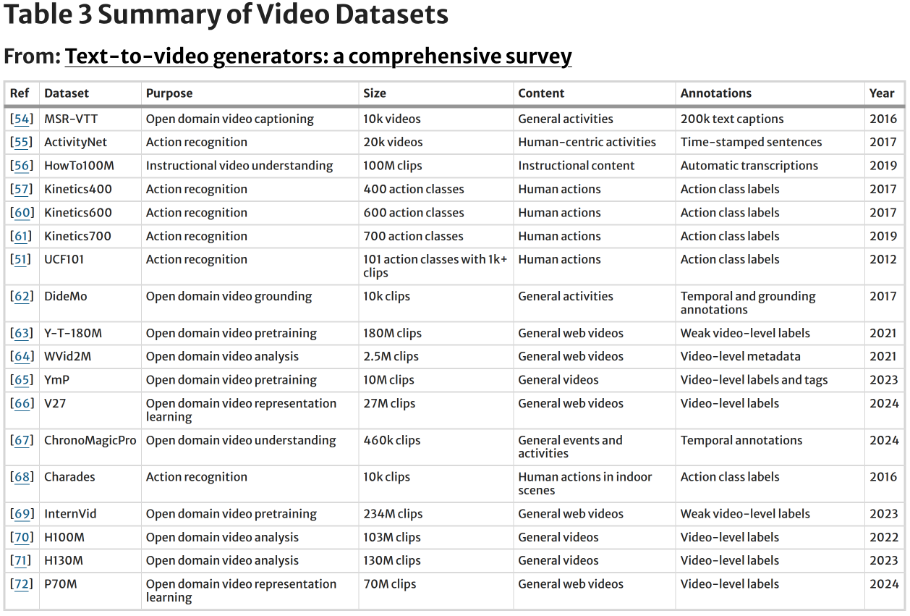
Abstract:Text-to-video (T2V) generation is an emerging domain that merges natural language processing with computer vision, facilitating the production of video material from textual narratives. This review offers a thorough analysis of the latest developments in T2V systems. We commence with a comprehensive literature survey, encompassing essential models and methodologies, frequently used datasets, and comparative evaluations of cutting-edge approaches. We subsequently analyze training methodologies and evaluation methods, emphasizing the quantitative and qualitative metrics employed to assess T2V performance. The paper examines many applications, including content creation, education, virtual reality, and e-commerce, while highlighting significant issues with videos generated by T2V models such as temporal consistency, semantic alignment, and scalability. Ultimately, we examine prospective future avenues to tackle these difficulties and broaden the scope of T2V technology. Authors:Muhammad Tanveer Jan, Mohammed G. Al-Jassani, Martinraj Nadar, Emmanuel Melchizedek Vunnava, Vangmai Chakrapani, Hayat Ullah, Abbas Khan, Sardar Ali Abbas & Borko Furht Conference / JournalJournal of Big Data, 12(1), 253 |