Research Effort
The NRT is motivated to integrate education and research and train graduate students in the six research Big Ideas. In this project we will leverage research conducted in our NSF Industry/University Cooperative Research Center for Advanced Knowledge Enablement (CAKE) at FAU. The CAKE Center was established in 2009, and in the ten-year period had 37 industry members with the total memberships of about $6 million. The Center successfully completed 45 applied industry projects. Borko Furht, Director and PI of the CAKE Center is also PI for the NRT proposal. The research focus of the Center is in the field of advanced knowledge enablement with the focus on areas of big data analytics, multimedia and data mining, video and multimedia processing, and cloud computing systems, sensors and networks. Research projects are interdisciplinary in their nature with the focus on applications in medical and healthcare, environmental, and mobile, public, and industrial applications. These are all synergetic activities needed to complete the applied research projects that we are planning to propose as part of research in the NRT project related to Harnessing the Data Revolution (HDR). Figure below illustrates research areas and related vertical applications. This section presents ongoing and envisioned projects in the following three data science and analytics areas: (1) Medical and Healthcare, (2) Industry Applications, and (3) Data Science Technologies. Within each of these areas, challenges and specific project examples are presented.
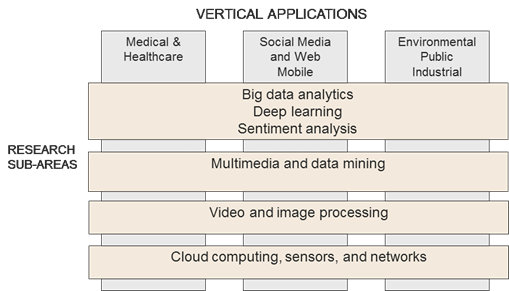
Research areas and related applications envisioned to be conducted within the proposed NRT project.
We should also stress out that majority of the presented projects are proposed by CAKE industry members and are funded or will be funded by industry memberships. Therefore, practically all projects will involve collaboration with application domain experts and industry partners. Students’ interaction with these experts and industry researchers will provide another key component of the NRT project, which is convergence training.
Medical and Healthcare

Challenges. The healthcare sector receives great benefits from the data science application in medical imaging. Data science can either be used for (i) analysis (pattern identification, hypothesis testing, risk assessment) or (2) prediction (machine learning models that predict the likelihood of an event occurring in the future, based on known variables).The most popular image-processing techniques focus on enhancement, segmentation, and denoising that allows deep analysis of organ anatomy, and detection of diverse disease conditions. With only 3 percent of U.S.-based data scientists working in the healthcare and hospital industry, the need for more trained data experts is growing quickly. Like any industry, healthcare workers should be familiar with statistics, machine learning, and data visualization.
Medical and healthcare projects, which we plan to investigate as part of the NRT include (i) Analyzing and detecting cognitive changes in older drivers using in-vehicle sensors and data analytics, (ii) Melanoma and brain tumor detection using data analytics techniques, and (iii) Medicare fraud detection using big data set.
Analyzing and Detecting Cognitive Changes in Older Drivers Using In-Vehicle Sensors and Data Analytics.
Tapen, Jang, Rosseli, Newman, and Furht are working on the project utilizing in-vehicle sensors to monitor drivers’ behavior and detect cognitive changes in older drivers. The objective of the project is to detect drivers who are in early stage of dementia and Alzheimer’s disease. We already established Driver Evaluation program at the Memory and Wellness Center at FAU with more than 600 individuals between ages of 60 and 85, and obtained IRB approval to open Driver Evaluation Registry. We intend to design in-vehicle sensor system consisting of two units, one measuring telematics data, and the other unit with two cameras for collecting vision data. When a driver is in situations that require complex cognitive functions and physical actions, in-vehicle sensors, including telematics and vision-sensing, will detect the situations and will trigger the maximum sampling and frame rates for both telematics and vision sensing units. Elderly people with cognitive impairment have difficulties in certain driving situations, such as backing up a car, making turns, lane change maneuvers, finding the way, stopping at a traffic signal or stop sign, and reacting to unexpected maneuvers. We will develop algorithms to analyze the data with the objective to detect cognitive changes, detect the drivers with early dementia, and prevent accidents.
Melanoma and Brain Tumor Detection Using Data Analytics Techniques. Development of AI may have significant impact in the future in important fields like medicine which may help to provide more efficient and affordable services to patients around the world. Intelligent diagnosis systems based on AI can aid doctors in detecting diseases. Recently, deep learning methods have been explored to provide solutions to image-based diagnosis tasks such as skin lesion classification. Effective diagnosis systems for lesion detection can improve diagnosis accuracy, which inherently reduces the number of biopsies made by dermatologists to determine the nature of the lesion, and can also aide with early detection of skin cancer like melanoma which can turn fatal if left undiagnosed and untreated. The diagnosis system may run on different types of personal devices like mobile phones and tablets to maximize its access to patients around the world. Skin cancer is a major medical problem. Every year in the United States alone 5.4 million skin cancer cases are reported. In the United States $8.1 billion is spent annually for skin cancer treatment, $3.3 billion of which is the total cost of treatment for melanoma alone. Melanoma is responsible for 75% of annual deaths due to skin cancer, claiming 10,000 lives annually although it only makes up 5% of skin cancer cases. Early detection for melanoma is vital for survival. If detected in its earliest stages, survival rate for melanoma is extremely high at 99% which falls down to only 14% in its latest stage. Marques and Furht are working on the cloud-based skin lesion diagnosis system using convolutional neural networks, with the objective to early detect melanoma based using lesion images. We are developing a deep learning based classifier that processes user submitted lesion images. The classifier is running on a server connected to the cloud based database. Deep learning based classifier performs quality checks and filters user requests before the request is sent to the diagnosis classifier. In the second phase of this project we plan to apply the same methodology to detect brain tumor based on brain images.
Medicare Fraud Detection. The application of machine learning to detect Medicare fraud is cutting-edge technology but not without its challenges. Medicare datasets are large and can easily be considered Big Data. This presents problems in both preparing the datasets for use and the creation and training of different machine learning models. Along with being considered Big Data, there are a lack of labels in the Medicare datasets that indicate what are fraudulent activities. The availability of the LEIE database helps, but this dataset contains only a fraction of known Medicare providers which leaves many unlabeled providers. The fraud labels, being limited in number, generates an imbalance between fraud and non-fraud labels in the dataset. This imbalance can produce inaccurate model predictions with a large number of both false negatives and false positives. The imbalance of fraud labels in a dataset can be quite severe with less than 0.1% being known as fraudulent. The number of examples is so rare that there are no discriminative patterns for which a machine learning model can successfully predict fraud. Bauder, Khoshgoftaar, Richter, and Herland are working on creating a model to predict a provider’s medical specialty based on the type and number of procedures performed. The idea is that if the predication differs from what the medical provider’s specialty is listed as, this could indicate a real-world discrepancy and possible misuse or fraud. This research proposes methods to lessen the impact of severe class imbalance between fraud and non-fraud cases, across multiple machine learning models.
Industry Applications

Challenges. Industry applications in data science and analytics involve a wide range of challenges. Deep Learning architectures, which are artificial neural networks characterized by having both a large breadth of neurons and a large depth of layers, benefit from training on Big Data. However, the size and complexity of the models combined with the size of the training data makes the training process very computationally expensive. Training a neural network model is the most computationally expensive process in a model’s development and is where it is molded to the example data to produce a usefully predictive model. Developing of efficient runtimes requires the integration of a robust Big Data platform and cutting-edge deep learning algorithms.
In the NRT example projects described next we plan to investigate: (i) The development of machine learning algorithms for big data on an industry platform referred to HPCC/ECL, (ii) Application of machine learning algorithms in automotive industry, and (iii) Developing new video coding algorithms using data analytics.
Developing Machine Learning Algorithms for Big Data on HPCC/ECL Platform. Khoshgoftaar and Kennedy are developing parallel neural network runtimes and algorithms specifically tailored for processing Big Data on the LexisNexis HPCC Systems Platform. Traditionally, HPCC Systems Platform is a commodity-computer-based cluster system that combines the power of many processors, CPUs, to perform high performance computing tasks. Since, Deep Learning is well suited for Big Data analytics and HPCC excels at Big Data processing, the project’s approach leverages the capabilities of HPCC systems and different third-party Python libraries to train single Deep Learning networks using multiple nodes in parallel. The member computers, or nodes, are connected via standard networking protocols and despite their relatively slow interconnect speeds, HPCC Systems Platform clusters have proven to be very effective in data-intensive computing tasks. Though these slower interconnect speeds pose new challenges, such systems drastically lower the financial barrier to entry. Purpose built systems can be extremely costly. Additionally, it is non-trivial to leverage a system topology such as HPCC Systems for efficient deep learning, but its development is crucial to providing a robust deep learning platform that is more accessible to researchers and institutions that may be more financially limited.
Application of Common Machine Learning Algorithms for Uses Cases in Auto Industry. Zhu, Furht, and Behara are applying machine learning techniques using JM Family Enterprises data sources to enable better decisions and smart actions in identified business domains and use cases. Currently, machine learning is not used in these targeted areas even though the potential benefits may be significant. In this project we work in partnership with JM Family’s R&D team to apply common machine learning algorithms for the selected use cases and develop proof-of-concepts to demonstrate the value of machine learning. The experiments conducted in the project include data cleaning, data integration, application of common machine learning algorithms for the targeted domains/use cases, testing of these algorithms, demonstrating/reporting the accuracy of the outcomes and presentation of the outcomes. The major milestones for this project include: (1) Preparation: Data acquisition and business domain knowledge understanding, (2) Data Analysis: Clean and integrate identified data sources and conduct knowledge discovery tasks, and (3) Algorithms: Apply common machine learning algorithms for the targeted use cases, validate results, and demonstrate accuracy of outcomes.
Developing New Video Coding Technologies Using Data Analytics. Video compression algorithms have continued to become more efficient and more complex over the last 30 years. Video encoder complexity has increased roughly 10x over the previous generation encoder while improving the compression efficiency by about 35% [HK1]. Increased complexity is a strong motivator to develop new tools and methods that reduce the complexity of video encoding. The Versatile Video Coding (VVC) standard currently being developed by MPEG follows this trend with 10x complexity increase over HEVC encoding. The increased complexity is a direct result of the large encoding option space that has to be evaluated before applying options that minimize video size while maximizing video quality. We have shown the effectiveness of reducing an encoding option search problem to a classification problem using machine learning [HK2]. Recent work shows the use of convolutional neural network (CNN) and long- and short-term memory (LSTM) network for mode prediction in High Efficiency Video Encoding (HEVC). The large option space available in VVC requires a learning framework such as deep learning to make effective encoding decisions. A large data set that captures the optimal decisions will be developed using a video from a variety of application domains. A family of networks may be necessary to effectively predict options given the dependencies in the option space. As a part of the proposed work we will explore solutions that minimize complexity of inference on edge devices. Hardware accelerated inference on low power devices will be a key to quick and wider acceptance of efficient but computationally complex technologies such as VVC.
Data Science Technologies

Challenges. The hottest data science technologies today include the following: predictive analytics, AI and pattern recognition, deep learning, data science automation, leveraging data from sensors (IoT), and intensive data and model simulation. This group of research will investigate and apply some of these technologies in the following projects: (i) User interests and behavior modeling in on-line networks, and (ii) Predicting symptom recovery time from sport-related concussions. The primary challenge in designing artificial intelligence for prediction of recovery time after sports related concussions is a lack of reliable training data. Privacy regulations such as HIPAA make access to anonymized medical data difficult [1] requiring an overreliance on subjective measures such as self-reported symptoms and circumstances of the injury. Much of this data was collected without plans for analysis, and as a result it tends to be noisy, have high rates of missing values, and consist of small feature sets. Population sizes are often small, meaning data tends to have few instances, limiting predictive abilities.
User Interests and Behavior Modeling in Online Networks. Zhu and xxx are currently designing deep learning algorithms for user interests and behavior modeling in online network systems. Online social networks, e-commerce systems, and communication networks are becoming increasingly popular in modern information systems. In networked systems, user behaviors are crucial to many events related to national security, crimes, cyber-bulling, clinical trials, as well as the health growth of the business. Many businesses are relying on user behavior analysis to maximize business revenue. For example, in online advertising, user interests directly impact on their response and actions to the displayed advertisement. In addition, user interests can further help determine the probability of an advertisement viewer becoming a buying customer. To date, existing methods for user response modeling mainly consider representing users as a static feature set and train machine learning classifiers to predict clicks. Such approaches do not consider temporal variance and changes of user behaviors, and solely rely on given features for learning. In our research, we propose to use deep learning based frameworks for user interest and user behavior modeling, by designing network-based user feature learning, and modeling user temporal-behavior to predict their future response. By using data from our industry partners, we collect page information displayed to the users as a temporal sequence, and use long-term-short-term memory (LSTM) network to learn features that represents user interests as latent features. Our pilot study and experiments on real-world data show that, compared to existing static set based approaches, considering sequences and temporal variance of user requests results in improvements in user response prediction and campaign specific user click prediction.
AI and Machine Learning Techniques to Predict Symptom Recovery Time from Sports-related Concussions. Khoshgoftaar and Lanset are developing predictive models that would serve as the foundation for a decision support system that could be used by doctors and athletic trainers to develop treatment plans for athletes who have suffered sport-related concussions. Due to the heterogeneous nature of brain injuries, targeted individualized treatment plans are consistently recommended to mitigate the long-term effects of sport-related concussions and ensure the best outcomes for the athletes. Our work so far has focused on early identification of the most serious injuries, specifically those with symptoms lasting longer than average. There is a lot of pressure on athletes to return to play as soon as possible after any injury, particularly at higher levels of competition (college or professional), but to return to play too early may exacerbate the long-term negative effects. One issue is that assessments are highly subjective, and may be performed by people who lack the appropriate expertise (athletic trainers, nurses or physicians who do not specialize in brain injuries). These assessments could benefit greatly from an intelligent system able to predict the severity of the injury and help guide an appropriate treatment plan. To address the challenge of a lack of clean and reliable training data, we are working on incorporating intelligent data sampling and imputation methods as well as feature engineering. Plans for future work will involve incorporating disparate datasets, including medical records, imaging, and injury reports into generalized models.